Curso Nbdev – Módulo con Clusters
Hacer todo el desarrollo
Ejemplo (Tema 4 Este es el que seria el tema 3)
Un uso común en el mundo de los datos es el uso de algoritmos de agrupamiento o clusterización. A continuación vamos a tomar distintos algoritmos de clusterización y vamos a ponerlos todos dentro de un módulo. Este simple ejemplo aunque sencillo nos mostrará de forma más extensa el uso de nbdev.
Primero generamos nuestro repositorio como lo hicimos en el ejemplo anterior.
Una vez con nuestro repositorio podemos iniciar nuestro repositorio de forma local y vamos a modificarlo para hacer el módulo de ejemplo.
Entendiendo un poco más
En la sección anterior vimos como construir un ejemplo básico, en este vamos a generar un módulo que tenga una biblioteca simple donde contenga ejemplos básicos de distintos tipos de clusterizaciones.
Entendamos la estructura que utiliza nbdev para generar nuestra nueva biblioteca, en el directorio nbs se encuentran los notebooks que vamos a modificar en nuestro ejemplo. al momento de creacion del repositorio una vez ejecutado el comando nbdev_new nos genera toda la estructura dentro de nuestro repositorio.
Si no se hizo de la misma forma que como se describió anteriormente, esto se puede hacer de forma manual, se ejecuta el mismo comando y se rellenan los campos solicitados
> nbdev_new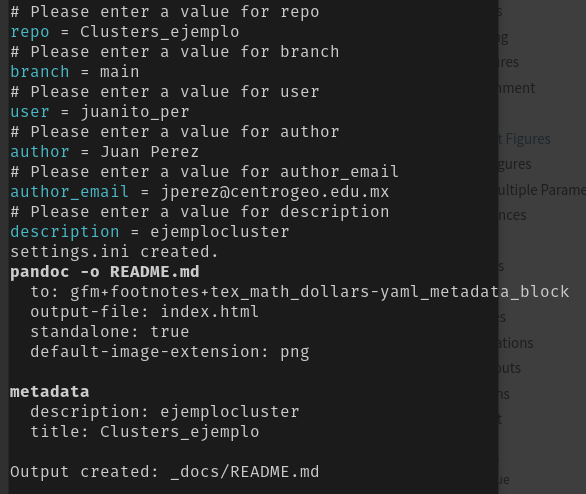
En el archivo settings.ini podemos ver las configuraciones, como ejemplo podemos ver que el archivo recien creado en el repositorio muestra los valores que se insertaron.
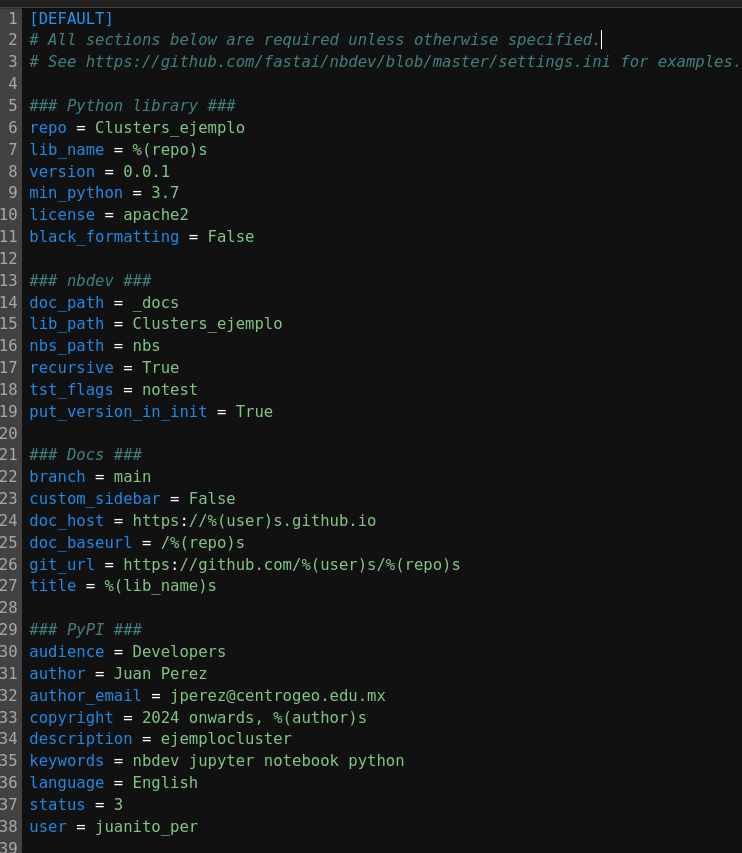
En este archivo se puede modificar cosas como la licencia, la url de la documentación, donde se aloja la documentación, el autor, el nombre de la biblioteca, la ruta en donde se localizan los notebooks, etc.
Como ya hemos visto para modificar algo en nuestra biblioteca es necesario hacerlo en los notebooks, con este propósito, nbdev generará los archivos correspondientes tanto de la documentación, como los archivos con el código que corresponden a los módulos de nuestra biblioteca.
También nbdev generará el archivo README.md el cual sirve como portada en nuestro repositorio. Para hace modificaciones a este, se deben hacer desde el archivo nbs/index.ipynb el cual nos permitirá una vez terminada nuestra biblioteca dar instrucciones simples para su instalación así como la posibilidad de añadir links a la documentación de nuestra biblioteca. Se puede generar únicamente el archivo README.md ejecutando el comando nbdev_readme, una vez ejecutado se puede abrir el archivo y ver las modificaciones realizadas.
nbdev_readmeSi se desea ver desde github será necesario actualizar los cambios en el repositorio, para esto haremos un ejemplo desde la terminal sólo se muestra como ejemplo pues un curso completo de git queda fuera de los temas de este curso.
git add README.md
git commit -m "Se modifica el README"
git pushgit add README.mdañade el archivo que se modifico y que se desea que actualizar, o bien añadir el archivo si no se tiene dentro de nuesto conjunto de archivos vigilados.git commit -m "Se modifica el README"se “comitea” es decir se añade a un registro de cambios de forma local los cambios hechos.-mes para añadir el comentario"Se modifica el README"a los cambios hechos, esto nos sirve como guía para ver qué cambios se han hecho y cúal fue la razón de nuestros cambios. Esto es muy útil cuando se buscan errores en el desarrollo y poder regresar al estado anterior.git pushSube los cambios hechos a el servidor de git, en nuestro caso lo va a subir a github pues el es servicio que determinamos usar.
Podemos ver las modificaciones en nuestro repositorio.
Otros comandos git
Otros comandos importantes de git
git clonesirve poara clonar repositoriosgit pullsirve para traer los cambios desde el servidor de git. El servidor depende de donde se tiene el servicio (github, gitlab o similares).git configconfigura distintos valores de el repositorio.git config –global user.name “Tu nombre”Cambia el valor de nombre de usuario de forma global.git config –global user.email “tumail@example.com”Cambia el valor global del mail.git initCrea un nuevo repositorio.git commit -a“Comitea” todos los archivos añadidos anteriormente al repositorio.git statusEnlista los archivos que se han cambiado dentro y aquellos que todavia se necesitan añadir o “comitear”.git checkout -b <nombre_rama>crea una nueva rama en el repositorio.git checkout <nombre_rama>cambia a la rama. git branchEnlista todas las ramas en el repositorio y en que rama te encuentras actualmente.git branch -d <nombre_rama>Borra la rama.
Regresar al ejemplo
Ya comprendimos un poco más como es la estructura que genera nbdev, ahora vamos hacer un ejemplo para generar nuevos módulos y como se hace el manejo de las dependencias y otras herramientas que están disponibles en nbdev.
Dentro del directorio nbs se encuentra el archivo 00_core.ipynb cambiemos el nombre de dicho archivo a 00_cluster.ipynb. Podemos abrir el archivo y como lo hicimos anteriormente este archivo nos servirá para generar tanto el código como la documentación de la biblioteca.
En la primera línea de código podemos observar que se tiene una directriz default_exp la cual nos sirve para determinar a qué módulo se exportarán lo que se genere dentro del notebook. Lo modificamos para que el módulo a exportar se llame cluster_ejemplo.
#| default_exp cluster_ejemploPodemos eliminar todas las demás celdas excepto la última. Esta última es la que indica que se genera el módulo. Esto es de importancia cuando se trabaja con múltiples notebooks y varios módulos.
#| hide
import nbdev; nbdev.nbdev_export()Vamos a modificar las cosas para hacer nuestra biblioteca. Añadimos el siguiente contenido a una nueva celda.
#| hide
#| export
from nbdev.showdoc import *
import matplotlib
import sklearn
import random
import numpy as np
import shapely
from sklearn.cluster import DBSCAN, HDBSCAN, OPTICS, KMeans
import matplotlib.pyplot as pltLa directriz #| hide esconde la celda al momento de generar un html, es especialmente útil para hacer la documentación mientras que la directriz #| export va a exportar a nuestro módulo lo que se encuentre en esta celda.
Añadimos un objeto para generar datos de forma aleatoria
#| export
class data_points:
"""Una clase que contiene a los datos"""
def __init__(self, n, min_x = 0, min_y = 0, max_x= 1, max_y=1, seed= None):
if seed != None:
random.seed(seed)
self.Points = np.random.uniform(low= min_x, high= max_x, size=(n, 2));
self.Points = [shapely.Point(x[0],x[1]) for x in self.Points]
def get_points(self):
"""Una funcion que para obtener los puntos"""
return self.Points
def get_Multypoint(self):
"""Regresa un objeto MultiPoint con los puntos"""
return shapely.geometry.MultiPoint(self.Points)
def get_X(self):
"""Regresa las coordenadas X"""
return [x.x for x in self.Points]
def get_Y(self):
"""Regresa las coordenadas X"""
return [x.x for x in self.Points]
def centroid(self):
"""Regresa el centroide de los puntos """
return shapely.centroid(self.get_Multypoint())Esta es una clase simple que nos sirve de ejemplo para ver algunas de las funcionalidades de nbdev. Cuando se contruye la documentación de forma automática nos genera una documentación simple como se muestra en la imagen Figure 3.

Todavía no vamos a hacer la documentación, antes de hacerlo vamos a añadir ciertas cosas. Se añaden las siguientes celdas como se puede observar ninguna de las celdas define nada nuevo simplemente se inicializa el objeto y se hace uso de sus métodos internos.
#| hide
datos_simples = data_points(40)datos_simples.get_points()datos_simples.get_points()datos_simples.get_Multypoint()datos_simples.get_X()datos_simples.get_Y()Todas estas celdas nos serviran para que hacer pruebas y comprobar las funcionalidades, en este caso estamos probando que los métodos funcionen de forma correcta.
Incluso se pueden hacer pruebas más complicadas, tomemos como ejemplo el código de la siguientes celda.
if len(datos_simples.get_X()) != len(datos_simples.get_Y()):
raise Exception("Si hay problema la evaluacion ")Este código generará un error si el número de elementos fuesen distintos, es claro que la clase como se encuentra implementada siempre pasara esta prueba. Las pruebas tienen que ser pensadas para que la idea las pasen sin importar como se hizo la implementación, como es el caso de la prueba anterior. Dentro del desarrollo podriamos cambiar la forma en la cual se generan los puntos y almacenar estos como si fueran dos lista, donde cada lista almacena los datos de cada coordenada, esto dependería de cada desarrollador. Si se tiene un error en la generación de estas lista, como puede ser simplemente generar la lista pero no llenarla con datos, el tamaño seria distinto y no pasaria la prueba. Para ver si el código dentro de los notebooks que generan de nuestros módulos pasan las pruebas se ejecuta la linea de comandos nbdev_test.
nbdev_testlo cual mostrará

Clase clusters
Vamos añadir una nueva clase a nuestro módulo, la cual llamaremos Clusters, esta clase nos sirve para generar clusters usando distintos algoritmos.
class Clusters:
"""
Clase para generar los clusters a partir de un objeto de la clase data_points
Esta clase se utiliza para generar los distintos tipos de clusterizaciones,
se almacena los datos en una estructura de datos y se le añaden las respectivas
classes
"""
def __init__(self, data_points_i, seed=1234):
if seed != None:
random.seed(seed)
self.data_structure = data_points_i
def KMeans(self, **kwargs):
"""
Se usa el algoritmo Kmeans para la obtencion de clusters,
las clases quedan almacenadas en .data_structure_classes_Kmeans.
Si se desea obtener el modelo se tiene que añadir
(ret_model = True) como parámetro.
"""
kmeans_c = KMeans(**kwargs)
classes_val = kmeans_c.fit_predict(self.data_structure.as_array())
self.data_structure.classes_Kmeans = classes_val
if 'ret_model' in kwargs and kwargs['ret_model']==True :
return kmeans_c
def DBSCAN(self, **kwargs):
"""
Se DBSCAN para la obtencion de clusters, las clases quedan almacenadas
en .data_structure_classes_DBSCAN. Si se desea obtener el modelo se tiene
que añadir (ret_model = True) como parámetro.
"""
db = DBSCAN(**kwargs).fit(self.data_structure.as_array())
self.data_structure.classes_DBSCAN = db.labels_
if 'ret_model' in kwargs and kwargs['ret_model']==True :
return db
def HDBSCAN(self, **kwargs):
"""
Se HDBSCAN para la obtencion de clusters, las clases quedan almacenadas
en .data_structure_classes_HDBSCAN. Si se desea obtener el modelo se tiene
que añadir (ret_model = True) como parámetro.
"""
hdb = HDBSCAN(**kwargs).fit(self.data_structure.as_array())
self.data_structure.classes_HDBSCAN = hdb.labels_
if 'ret_model' in kwargs and kwargs['ret_model']==True :
return hdb
def OPTICS(self, **kwargs):
"""
Se usa el algoritmo OPTICS para la obtencion de clusters,
las clases quedan almacenadas en .data_structure_classes_OPTICS.
Si se desea obtener el modelo se tiene que añadir
(ret_model = True) como parámetro.
"""
optics= OPTICS(**kwargs).fit(self.data_structure.as_array())
self.data_structure.classes_OPTICS = optics.labels_
if 'ret_model' in kwargs and kwargs['ret_model']==True :
return opticsPara exportar la clase al módulo es necesario añadir la directriz #| export al inicio de la celda. Adicionalmente añadimos pruebas simples usando los datos que ya se generaron.
cluster_all = Clusters(datos_simples)cluster_all.DBSCAN()cluster_all.KMeans()cluster_all.HDBSCAN()cluster_all.OPTICS()Como estas celdas nos sirven de pruebas vamos a añadir la directriz #| hide para evitar que estas sean parte de la documentación. Ahora podemos añadir ejemplos del uso de la clase cluster e incluso añadir como se usan los métodos.
Documentación
Para generar la documentación se hace usando el comando
nbdev_docsEn este caso, en la terminal podemos observar lo que se muestra en la imagen Figure 5, como se observa en el directorio _docs se encuentra un archivo html que puede abrirse usando un navegador y se puede ver la documentación y se puede ver que sólo muestra el ‘docstring’ generado por las clase como en la figura Figure 3 y el respectivo para la clase Clusters.

Para mostrar un poco más lo que hace nuestra clase simple añadimos las siguientes celdas
show_doc(Clusters.KMeans)show_doc(Clusters.DBSCAN)show_doc(Clusters.HDBSCAN)show_doc(Clusters.OPTICS)Estas mostrarán lo que se haya puesto dentro de los ‘docstrings’ de los métodos en la clase Cluster.
También podemos generar la documentación y hacer una previsualización haciendo uso del comando
nbdev_previewlo cual nos mostrará
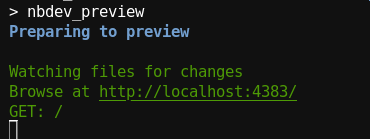
llevándonos a la documentación de forma local.
Muestre los métodos para la clase data_points en la documentación
Mas documentación
Podemos hacer uso de las facilidades de los jupyter notebooks para generar ejemplos y tutoriales, para esto vamos hacer dentro del mismo notebook.
Creamos un conjunto de datos usando los distintos métodos en las clases que ya hicimos.
datos_simples_3 = data_points(500, min_x = 0.6, min_y= 0.6, max_x= 1.0, max_y= 1.0 )
datos_simples_2 = data_points(500, min_x = 0.0, min_y= 0.6, max_x= 0.4, max_y= 1.0 )
datos_simples_1 = data_points(500, min_x = 0.6, min_y= 0.0, max_x= 1.0, max_y= 0.4 )
datos_simples_0 = data_points(500, min_x = 0.0, min_y= 0.0, max_x= 0.4, max_y= 0.4 )Unimos todos los puntos con el método add_points de la clase data_points.
datos_simples_0.add_points(datos_simples_1)
datos_simples_0.add_points(datos_simples_2)
datos_simples_0.add_points(datos_simples_3)Veamos los puntos dentro de nuestra estructura.
datos_simples_0.get_Multypoint()Ahora inicialicemos nuestro objeto Clusters
cluster_all = Clusters(datos_simples_0)Y ahora podemos hacer uso de los algoritmos usando los métodos de las distintas las clusterizaciones.
cluster_all.OPTICS()
cluster_all.HDBSCAN()
cluster_all.DBSCAN(eps=0.1, min_samples=10)
cluster_all.KMeans()Y visualizemos las clusterizaciones
fig, ax = plt.subplots(1,1, figsize=(6,6))
plt.scatter(
cluster_all.data_structure.get_X(),
cluster_all.data_structure.get_Y(),
c = cluster_all.data_structure.classes_Kmeans
)fig, ax = plt.subplots(1,1, figsize=(6,6))
plt.scatter(
cluster_all.data_structure.get_X(),
cluster_all.data_structure.get_Y(),
c = cluster_all.data_structure.classes_DBSCAN
)fig, ax = plt.subplots(1,1, figsize=(6,6))
plt.scatter(
cluster_all.data_structure.get_X(),
cluster_all.data_structure.get_Y(),
c = cluster_all.data_structure.classes_HDBSCAN
)fig, ax = plt.subplots(1,1, figsize=(6,6))
plt.scatter(
cluster_all.data_structure.get_X(),
cluster_all.data_structure.get_Y(),
c = cluster_all.data_structure.classes_OPTICS
)Si se ejecuta nbdev_preview o nbdev_docs en la documentación mostrará el ejemplo dentro de la misma.
Ahora para preparar verificar que todo esta bien ejecutamos
nbdev_prepareLo cual mostrará si no hay ningun problema. En el fondo lo que hace nbdev_prepare preprocesar los archivos dentro de nbs y generar los
Publicar todo
Vamos a entender un poco más que es lo que pasa cuando se hace la publicación de la documentación generada. Ya hemos dicho que por abajo nbdev usa Quarto para la generación de la documentación, lo que sucede es que nuestros notebooks son preprocesados generando notebooks que se usan como base para convertirlos a documentos html. Estos notebooks se encuentran en el directorio _proc (se genera cuando se executa nbdev_docs) los cuales tienen en sus celdas directrizes de Quarto para generar los resultados deseados. Podemos inspeccionar estos archivos comprobando observar que son similares a los notebook originales, si se inspecciona el directorio _docs se vera que los documentos html son los que fueron generados a partir de los notebooks en _prod.
De esta forma hemos generado todo para nuestra biblioteca, tiene documentación y haciendo uso de nbdev_prepare se generan los módulos para poder instalar. Esto nos sirve si se desea publicar la documentación en un servicio distinto a github.
A continuación vamos a integrar todo en Github para que tanto las pruebas como la creación de la documentación realizadas usando github-actions como ya se hizo en los primeros pasos de este curso con la creación de una biblioteca muy sencilla.
Como hemos añadido bibliotecas y hemos modificado las cosas si intentamos seguir los pasos descritos con anterioridad ni las prueba ni la documentación podrán ser realizadas de forma correcta. Por tal motivo vamos a dar una explicación más extensa de los pasos.
Entendiendo github-actions.
Las acciones de Github actions nos permiten realizar acciones automatizadas dentro de nuestro directorio de Github, en nuestro caso dichas acciones se encuentran dentro de los archivos que se encuentran en el directorio .github dentro del directorio workflows los cuales son deploy.yaml y test.yaml. Estos dos archivos controlan los dos flujos de trabajo que se realizan dentro de github. Vamos a modificarlos y explicar un poco que hacen cada uno.
El archivo deploy es el que utilizamos para generar la documentación, vamos a sustituir el contenido del archivo con el que se encuentra en la celda siguiente:
Archivo deploy.yaml
name: Deploy to GitHub Pages
on: [workflow_dispatch, pull_request, push]
permissions:
contents: write
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: actions/setup-python@v4
- name: Install Dependencies and create documentation
shell: bash
run: |
python -m pip install --upgrade pip
pip install -Uq git+https://github.com/fastai/ghapi.git # you need this for enabling pages
pip install -Uq git+https://github.com/fastai/fastcore.git
pip install -Uq git+https://github.com/fastai/execnb.git
pip install -U git+https://github.com/fastai/nbdev.git
wget -q $(curl https://latest.fast.ai/pre/quarto-dev/quarto-cli/linux-amd64.deb)
sudo dpkg -i quarto*.deb
pip install -Uq matplotlib
pip install -Uq setuptools
pip install -Uq scikit-learn
pip install -Uq shapely
nbdev_docs
# pip install -e ".[dev]"
- name: Deploy to GitHub Pages
uses: peaceiris/actions-gh-pages@v4
with:
github_token: ${{ secrets.GITHUB_TOKEN }}
force_orphan: true
publish_dir: ./_docs
# The following lines assign commit authorship to the official GH-Actions bot for deploys to `gh-pages` branch.
# You can swap them out with your own user credentials.
user_name: github-actions[bot]
user_email: 41898282+github-actions[bot]@users.noreply.github.comExpliquemos a grandes rasgos lo que esta haciendo este archivo. Las primeras lineas le dan nombre a la acción y cuando se realiza esta. En este caso llamamos a la acción ‘Deploy to GitHub Pages’ y la acción será realizada cuando se solicite de forma manual (‘workflow_dispatch’) cuando se haga una petición pull (‘pull_request’) o bien quando se realize un push.
name: Deploy to GitHub Pages
on: [workflow_dispatch, pull_request, push] El trabajo que va a realizar se denomina ‘deploy’ el cual utilizará una máquina virtual con la versión más reciente de ubuntu (‘ubuntu-latest’).
En las siguientes lineas estamos dando permiso a la maquina virtual de poder escribir dentro de nuestro repositorio.
permissions:
contents: writeDespues el trabajo consiste en los siguientes pasos:
- uses: actions/checkout@v3
- uses: actions/setup-python@v4Utiliza las acciones actions/checkout@v3 y actions/setup-python@v4 que son acciones que tenemos estandarizadas dentro de github actions. Las cuales hace un check out del repositorio dentro de la maquina virtual para realizar el trabajo. actions/setup-python@v4 instala python dentro de la maquina virtual.
El siguiente paso lo llamamo ‘Install Dependencies and create documentation’ aquí podemos ver que hacemos un conjunto de acciones que hicimos con anterioridad cuando instalamos las cosas necesarias para hacer uso de Nbdev, Git, Quarto, etc.
- name: Install Dependencies and create documentation
shell: bash
run: |
python -m pip install --upgrade pip
pip install -Uq git+https://github.com/fastai/ghapi.git # you need this for enabling pages
pip install -Uq git+https://github.com/fastai/fastcore.git
pip install -Uq git+https://github.com/fastai/execnb.git
pip install -U git+https://github.com/fastai/nbdev.git
wget -q $(curl https://latest.fast.ai/pre/quarto-dev/quarto-cli/linux-amd64.deb)
sudo dpkg -i quarto*.deb
pip install -Uq matplotlib
pip install -Uq setuptools
pip install -Uq scikit-learn
pip install -Uq shapely
nbdev_docsPongamos especial atención en las últimas líneas, aquí instalamos las dependencias que se utilizaron en hacer nuestra biblioteca y son necesarias para que los notebooks que hicimos puedan correr. Una vez instaladas las dependencias podemos generar la documentación con ‘nbdev_docs’.
Como en la máquina virtual ya generamos nuestra documentación ahora vamos a ponerla dentro de un nuevo ‘branch’, por eso le tenemos que dar permiso para escribir, dentro del repositorio y usar ese ‘branch’ para publicar la documentación usando el siguiente paso:
- name: Deploy to GitHub Pages
uses: peaceiris/actions-gh-pages@v4
with:
github_token: ${{ secrets.GITHUB_TOKEN }}
force_orphan: true
publish_dir: ./_docs
# The following lines assign commit authorship to the official GH-Actions bot for deploys to `gh-pages` branch.
# You can swap them out with your own user credentials.
user_name: github-actions[bot]
user_email: 41898282+github-actions[bot]@users.noreply.github.comEsto usa las acciones descritas en peaceiris/actions-gh-pages@v4 las cuales ya estan automatizadas para generar un nuevo branch con nombre ‘gh-pages’ y añadir el contenido de la documentación dentro de el branch. Lo que se añade dentro del branch es lo que se encuentra dentro del directorio ’./_docs’. ‘github_token’ nos permite autenticar el trabajo realizado por el flujo de trabajo. Los parámetros de ‘user_name’ y ‘user_email’ permiten avisar que acciones fueron realizadas por el script ‘peaceiris/actions-gh-pages@v4’ y las cuales aparecerán que fueron realizadas por github-pages bot. Estas acciones nos enviaran un mail con el resultado del trabajo realizado, es decir si este fue exitoso o no.
Archivo test.yaml
En el caso de las pruebas estas se hacen en las acciones en el archivo ‘test.yaml’ y vamos a remplazar su contenido por el código siguiente:
name: Test CI
on: [workflow_dispatch, pull_request, push]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: actions/setup-python@v4
- name: Install Nbdev Dependencies
shell: bash
run: |
python -m pip install --upgrade pip
pip install -Uq git+https://github.com/fastai/ghapi.git # you need this for enabling pages
pip install -Uq git+https://github.com/fastai/fastcore.git
pip install -Uq git+https://github.com/fastai/execnb.git
pip install -U git+https://github.com/fastai/nbdev.git
- name: Install package dependencies
shell: bash
run: |
python -m pip install -Uq matplotlib
python -m pip install -Uq setuptools
python -m pip install -Uq scikit-learn
python -m pip install -Uq shapely
- name: Test the package
shell: bash
run: |
echo "Check we are starting with clean git checkout"
if [[ `git status --porcelain -uno` ]]; then
git diff
echo "git status is not clean"
false
fi
echo "Trying to strip out notebooks"
nbdev_clean
echo "Check that strip out was unnecessary"
git status -s # display the status to see which nbs need cleaning up
if [[ `git status --porcelain -uno` ]]; then
git status -uno
echo -e "!!! Detected unstripped out notebooks\n!!!Remember to run nbdev_install_hooks"
echo -e "This error can also happen if you are using an older version of nbdev relative to what is in CI. Please try to upgrade nbdev with the command `pip install -U nbdev`"
false
fi
nbdev_export
if [[ `git status --porcelain -uno` ]]; then
echo "::error::Notebooks and library are not in sync. Please run nbdev_export."
git status -uno
git diff
exit 1;
fi
if [ ! $SKIP_TEST ]; then
nbdev_test --flags "$FLAGS"
fi
De forma similar el nombre del trabajo es ‘Test CI’ los trabajos se se realizan cuando se hace una petición de forma manual o se hace un pull o un push.
Se corre en una máquina virtual con ubuntu ‘runs-on: ubuntu-latest’ y hace un checkout, se instala python y nbdev junto con sus dependencias.
En el siguiente paso se instalan las dependencias de la biblioteca en la maquina virtual.
- name: Install package dependencies
shell: bash
run: |
python -m pip install -Uq matplotlib
python -m pip install -Uq setuptools
python -m pip install -Uq scikit-learn
python -m pip install -Uq shapely
Y en lo que resta del código verifica si estas cosas y hace las pruebas usando nbdev_test dentro de la maquina virtual
- git se verifica el contenido de la versión del repositorio que se encuentra en la máquina virtual
- Verifica que los notebooks no tengan cosas inecesarias, si no es así marca error
- Construye la biblioteca dentro de la máquina virtual usando ‘nbdev_export’
- Hace las pruebas usando ‘nbdev_test’
name: Test the package
shell: bash
run: |
echo "Check we are starting with clean git checkout"
if [[ `git status --porcelain -uno` ]]; then
git diff
echo "git status is not clean"
false
fi
echo "Trying to strip out notebooks"
nbdev_clean
echo "Check that strip out was unnecessary"
git status -s # display the status to see which nbs need cleaning up
if [[ `git status --porcelain -uno` ]]; then
git status -uno
echo -e "!!! Detected unstripped out notebooks\n!!!Remember to run nbdev_install_hooks"
echo -e "This error can also happen if you are using an older version of nbdev relative to what is in CI. Please try to upgrade nbdev with the command `pip install -U nbdev`"
false
fi
nbdev_export
if [[ `git status --porcelain -uno` ]]; then
echo "::error::Notebooks and library are not in sync. Please run nbdev_export."
git status -uno
git diff
exit 1;
fi
if [ ! $SKIP_TEST ]; then
nbdev_test --flags "$FLAGS"
fiComo se observa, los pasos anteriores son los que ya hemos desde la instalación y la construcción de la biblioteca.
Con los archivos que hemos modificado hemos dado las instrucciónes para que estas acciones se desarrollen en máquinas virtuales en servidores de github.
Si todo se encuentra en orden podemos salvar los archivos, hacer un commit, y hacer un push. Como las acciones se ejecuntan cuando se hace un push podemos ver en las acciones de github e ir a la página de github para verificar que el flujo de trabajo funciona de forma adecuada. En el menu Actions del repositrio.

En este menú veremos las acciones que se llevan a cabo del lado izquierdo en nuestro caso:
- Deploy to Github Pages
- Test CI
- pages-build-deployment (ejecutado al hacer el branch ‘gh-pages’)
En el centro una lista con los commits realizado y el resultado de las acciones que se llevaron acabo y si estas tuvieron éxito (✅) o no (❌).
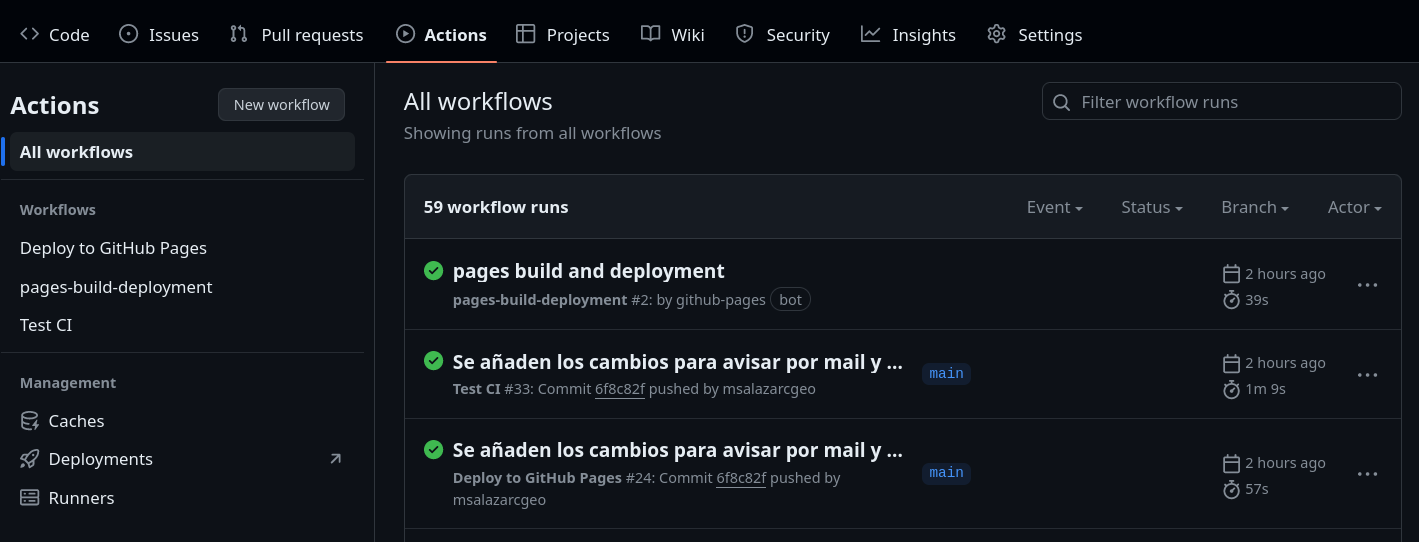
Para habilitar nuestra página de documentación se tienen que seguir los mismos pasoes que vimos anteriormente y se selecciona el branch de ‘gh-pages’ para habilitar la documentación.
Comentarios finales
Como hemos visto nbdev tiene muchas funcionalidades, esto nos permite tener una integración continua para generar tanto nuestros módulos como la documentación de los mismo sin hacer mucho esfuerzo extra.